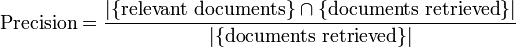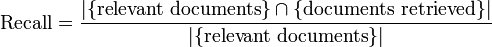pada prinsipnya menurut Houghton (1977)
sistem temu kembali informasi adalah penelusuran yang merupakan
interaksi antara pemakai dan sistem dan pernyataan kebutuhan pengguna
diekspresikan sebagai suatu istilah tertentu. Selanjutnya dinyatakan
bahwa komponen fundamental dari sistem temu kembali informasi adalah
sebagai berikut:
- penyimpanan (storage), yaitu menyangkut analisis subjek oleh pengindeks dan penerjemahan dari istilah ke dalam bahasa pengindeksan oleh sistem.
- proses temu kembali (retrieval), yaitu berkaitan dengan analisis dan pernyataan penelusuran; penerjemahan pertanyaan dalam bahasa pengindeksan oleh sistem; serta formulasi dari strategi penelusuran diekspresikan sebagai suatu istilah tertentu.
Lancaster (1979) dan Doyle (1975)
memandang sistem temu-kembali informasi dalam konteks siklus transfer
informasi, mengatakan bahwa suatu sistem temu-kembali informasi
merupakan subsistem (tahap luaran) dari sistem informasi. Lancaster juga
mengatakan bahwa sistem temu-kembali informasi terdiri dari enam
subsistem:
- Subsistem dokumen;
- subsistem indexing;
- subsistem kosa kata;
- subsistem penelusuran;
- antar-muka (interface) pemakai dengan sistem;
- subsistem penyesuaian/pencocokan.
Dokumen sebagai objek data dalam Sistem
Temu Kembali Informasi merupakan sumber informasi. Dokumen biasanya
dinyatakan dalam bentuk indeks atau kata kunci. Kata kunci dapat
diekstrak secara langsung dari teks dokumen atau ditentukan secara
khusus oleh spesialis subjek dalam proses pengindeksan yang pada
dasarnya terdiri dari proses analisis dan representasi dokumen.
Pengindeksan dilakukan dengan menggunakan sistem pengindeksan tertentu,
yaitu himpunan kosa kata yang dapat dijadikan sebagai bahasa indeks
sehingga diperoleh informasi yang terorganisasi. Sementara itu,
pencarian diawali dengan adanya kebutuhan informasi pengguna. Dalam hal
ini Sistem Temu Kembali Informasi berfungsi untuk menganalisis
pertanyaan (query) pengguna yang merupakan representasi dari
kebutuhan informasi untuk mendapatkan pernyataan-pernyataan pencarian
yang tepat. Selanjutnya pernyataan-pernyataan pencarian tersebut
dipertemukan dengan informasi yang telah terorganisasi dengan suatu
fungsi penyesuaian (matching function) tertentu sehingga
ditemukan dokumen atau sekumpulan dokumen. Proses tersebut di atas dapat
diilustrasikan seperti gambar berikut:

Pada bagan yang dibuat oleh Lauren B.
Doyle Juga terdapat kemiripan pada bagan sistem temu kembali informasi
milik Lancaster, berikut ini diagram Lauren B. Doyle:

Ada persamaan antara penjelasan dari
Lancaster (1979) dengan Tague-Sutcliffe (1996), hanya saja ada sedikit
perbedaaan yaitu pada komponen penilaian relevansi. Lebih jelasnya,
Tague-Sutcliffe (1996) melihat Sistem Temu Kembali Informasi sebagai
suatu proses yang terdiri dari 6 (enam) komponen utama yaitu:
- Kumpulan dokumen
- Pengindeksan
- Kebutuhan informasi pemakai
- Strategi pencarian
- Kumpulan dokumen yang ditemukan
- Penilaian relevansi
Secara garis besar komponen-komponen
Sistem Temu Kembali menurut Tague-Sutcliffe (1996) dapat diilustrasikan
seperti gambar berikut:

Pada intinya menurut Di Nubila (1994)
dalam sistem temu kembali informasi terdapat tiga komponen utama yang
saling mempengaruhi, yaitu:
- kumpulan dokumen;
- kebutuhan informasi pengguna;
- proses pencocokan (matching) antara keduanya
secara garis besar menurut Hasibuan (1996) bisa juga dikatakan bahwa komponen sistem temu kembali informasi terdiri dari:
- pemakai (user), adalah poin utama dari semua sistem temu kembali informasi, karena tujuan utama dari setiap penyimpanan informasi adalah menemukan kembali informasi dari sumbernya (database) kepada pemakai.
- dokumen, Struktur dokumen dalam suatu basis data elektronis memegang peranan penting dalam meningkatkan kinerja sistem temu kembali informasi. Stuktur tersebut dibentuk oleh berbagai ciri yang menjadi bagian dari suatu dokumen. Ciri-ciri tersebut meliputi : kata-kata indeks (Indeks terms), kata-kata bebas (Free text terms), pengarang, referensi (Cited documents), sitasi (Citing document), afiliasi pengarang,matcher-machine.
- Ada fungsi matcher-machine dalam sistem temu kembali informasi, yaitu:
- Fungsi exact match, adalah pencocokan dimana representasi suatu pertanyaan persis sama atau harus sesuai dengan representase dokumen, agar dokumen tersebut dapat terambil (retrieved).
- Fungsi partial match atau pencocokan sebagian, yaitu representasi pertanyaan hanya sebagian saja yang sama dengan representasi dokumen. Pencocokan sebagian ini dikenal dengan pemenggalan (truncation).
Komponen dasar sistem temu kembali informasi menurut Chowdury (1999) ada 3 yaitu:
- Dokumen atau sumber informasi
- Query atau Pemakai
- Fungsi Pencocokan (matching function)
kumpulan dokumen yang ada dalam sistem diwakili oleh kata-kata kunci atau kata indeks sebagai pendekatan dalam penelusuran. Sedangkan query
(permintaan) adalah rumusan pertanyaan yang dimasukkan ke sistem dan
fungsi pencocokan di sini mempertemukan antara sumber informasi yang
disimpan di sistem dengan permintaan pemakai.
Secara sederhana, penjelasan dari Di
Nubila (1994), Hasibuan (1996) dan Chowdury (1999) hampir sama dengan
yang digambarkan oleh Ingwersen (2002) sebagai ilustrasi model temu
kembali informasi seperti gambar berikut:

“Representation” dari gambar di sebelah kiri menunjukkan representasi dokumen, data dan informasi. “Query” pada komponen sebelah ‘kanan merupakan representasi dari pertanyaan pengguna, serta “matching function”
komponen yang di tengah merupakan fungsi pencocokan antara representasi
data/dokumen dengan pertanyaan. Kemudian dalam “Temu lembali lnformasi”
kurang lebih sama dengan penjelasan tentang prinsip temu kembali
informasi menurut Houghton (1977), ilustrasi dari temu kembali informasi
dapat digambarkan sebagai berikut:

Selanjutnya dalam “Sistem Temu kembali
Informasi”, sebagai suatu sistem, sistem temu kcmbali informasi mcmiliki
bcbcrapa bagian yang membangun sistem secara keseluruhan. Gambaran
bagian-bagian yang terdapat pada suatu sistem temu kembali informasi
hampir sama seperti penjelasan tentang subsistem temu kembali informasi
menurut Lancaster (1979) dan Doyle (1975) yang digambarkan sebagai
berikut:

- Text Operations (operasi terhadap teks) yang meliputi pemilihan kata-kata dalam query maupun dokumen dalam pentransformasian dokumen atau query menjadi terms index (indeks dari kata-kata).
- Query Formulation (formulasi terhadap query) yang memberi bobot pada indeks kata-kata query.
- Ranking, mencari dokumen-dokumen yang relevan terhadap query dan mengurutkan dokumen tersebut berdasarkan kesesuaiannya dengan query.
- Indexing, membangun data indeks dari koleksi dokumen. Dilkakukan terlebih dahulu sebelum pencarian dokumen, sistem temu kembali informasi menerima query dari pengguna, kemudian melakukan perangkingan terhadap pada koleksi berdasarkan kesesuaiannya dengan query. Hasil perangkingan yang diberikan kepada pengguna merupakan dokumen yang sistem, relevan dengan query, namun relevansi dokumen terhadap suatu query merupakan penilaian pengguna yang subjektif dan dipengaruhi banyak faktor.
Untuk memahami Information retrieval, Chu (2003) menjelasakan bahwa pada prinsipnya, sistem temu kembali informasi memiliki beberapa komponen sebagai berikut:
- Sebuah pangkalan data (database) sebagai tempat meletakkan dan menyimpan wakil dari dokumen atau informasi.
- Sebuah mekanisme pencarian untuk menemukan apa yang sudah tersimpan di pangkalan data.
- Seperangkat bahasa pencarian, yaitu bahasa yang digunakan manusia pengguna sistem dan yang dikenali oleh mesin komputer yang ia gunakan.
- Sebuah antamuka (interface), yaitu segala sesuatu yang terlihat, terdengar, atau tersentuh oleh pengguna ketika dia melakukan pencarian informasi.
Menurut Chu (2003), Komponen-komponen tersebut saling berkaitan untuk membentuk sebuah model seperti gambar berikut:

Sedangkan menurut Hasugian (2007) ada lima komponen Sistem temu kembali informasi yaitu :
1. Pengguna
Pengguna adalah orang yang menggunakan
atau memanfaatkan Sistem temu kembali informasi dalam kegiatan
pengelolaan dan pencarian informasi. Berdasarkan perannya, pengguna
Sistem temu kembali informasi dibedakakan atas 2 (dua) kelompok yaitu:
- Pengguna (user) adalah seluruh pengguna Sistem temu kembali informasi yang menggunakan Sistem temu kembali informasi baik untuk pengelolaan (input data, backup data, maintenance atau lainnya) maupun untuk keperluan pencarian/penelusuran informasi.
- pengguna akhir (end user) adalah pengguna yang hanya menggunakan Sistem temu kembali informasi untuk keperluan pencarian dan atau penelusuran informasi.
Query adalah format bahasa permintaan yang di input (dimasukan) oleh pengguna kedalam Sistem temu kembali informasi. Dalam interface (antar
muka) Sistem temu kembali informasi selalu disediakan kolom/ruas
sebagai tempat bagi pengguna untuk mengetikkan (menuliskan) query nya. Dalam OPAC perpustakaan disebut “Search expression”. Pada kolom itulah pengguna mengetik/ menuliskan bahasa permintaanya (query), dan setelah query itu dimasukkan selanjutnya mesin akan melakukan proses pemanggilan (recall) terhadap dokumen yang diinginkan dari database.
3. Dokumen
Dokumen adalah istilah yang digunakan
untuk seluruh bahan pustaka, apakah itu artikel, buku, laporan
penelitian dsb. Seluruh bahan pustaka (dimasukkan) dan disimpan dalam database (pangkalan data). Media penyimpanan database ini ada yang berbentuk CD-ROM ada juga yang berbentuk harddisk. Database ini ada yang bisa diakses secara online dan ada juga yang diakses secara off line. Biasanya database yang bisa diakses secara online dapat diakses secara bersamaan (multy user), sedangkan yang sifatnya off line hanya dapat digunakan oleh seorang saja dalam waktu yang sama (single user).
4. Indeks Dokumen
Indeks adalah daftar istilah atau kata (list of terms). Dokumen yang dimasukkan/disimpan dalam database diwakili
oleh indeks, Indeks itu disebut indeks dokumen. Fungsinya adalah
representasi subyek dari sebuah dokumen. Indeks memiliki tiga jenis
yaitu :- Indeks subyek adalah menentukan subyek dokumen pada istilah mana/apa yang menjadi representasi subyek dari sebuah dokumen.
- Indeks pengarang adalah mementukan nama pengarang mana yang menjadi representasi dari suatu karya.
- Indeks bebas adalah menjadikan seluruh kata/istilah yang terdapat pada sebuah dokumen menjadi sebuah representasi dari dokumen, terkecuali stopword. Stopword adalah kata yang tidak di indeks seperti : yang, that, meskipun, di, ke, dan lain-lain atau seluruh kata sandang/partikel.
5. Pencocokkan (Matcher Fungtion)
Pencocokkan istilah (query) yang dimasukkan oleh pengguna dengan indeks dokumen yang tersimpan dalam database adalah
dilakukan oleh mesin komputer. Komputerlah yang melakukan proses
pencocokkan itu dalam waktu yang sangat singkat sesuai dengan kecepatan memory dan processing yang
dimiliki oleh komputer itu. Komputer hanya dapat melakukan pencocokan
berdasarkan kesamaan istilah, komputer tidak bisa berfikir seperti
manusia sebab mesin komputer tersebut hanyalah “artificial intelegence” (kecerdasan buatan). Oleh karena itu sering terjadi “ambiguitas” atau kesalahan makna untuk sebuah istilah.
Dalam proses pencarian informasi terjadi
interaksi antara pengguna dengan sistem (mesin) baik secara langsung
maupun tidak langsung. Secara umum interaksi antara pengguna dengan
sistem dalam proses pencarian informasi dapat dinyatakan seperti pada
gambar berikut:

Skema gambar user yang menggunakan sistem temu kembali informasi dinyatakan seperti gambar berikut: